
Almacenar datos en un servidor web IoT usando peticiones HTTP POST


Como se explicaba en el primer artículo de la serie almacenar los datos obtenidos por los dispositivos de la internet de las cosas, aunque los datos que se guardan terminan en un servidor MySQL o MariaDB y se utiliza el lenguaje PHP para manipularlos a la entrada y a la salida, el flujo de información entre el equipo electrónico y la base de datos se produce usando un servidor web con el que se comunica según el protocolo HTTP.
En los inicios de la definición del protocolo HTTP se contó con usos equiparables al que se está describiendo pero el hecho es que finalmente no se ha explotado por completo por diversas razones, en parte de seguridad y en parte porque nunca se avanzó en la definición de un protocolo más específico ni más eficiente así que en la actualidad, especialmente en los servidores públicos, lo más frecuente es usar una conexión HTTP que hace una petición POST al servidor para almacenar la información o una GET para recuperarla, normalmente para mostrar una página web que la presenta e incluso sobre la que se puede interactuar.
El texto más básico enviado al servidor en una petición HTTP POST incluye una línea con el tipo de petición (POST) la ruta hasta la página web que almacenará la información y la versión del protocolo HTTP; otra línea con el nombre del host (lo que permite servidores virtuales en el mismo servidor y/o en la misma dirección IP) y por fin otra que contiene los datos que se graban separados entre ellos por el signo & y de las líneas anteriores por una en blanco.
|
1
2
3
4
|
POST /iot/grabar_temperatura HTTP/1.1
Host: polaridad.es
ne=muelle+de+carga&tp=10.26&cr=2.18
|
En el ejemplo de arriba, un servidor llamado polaridad.es contendría una página en /iot/grabar_temperatura para gestionar la información utilizando para comunicarse la versión 1.1 del protocolo HTTP
Puede verse que se usan dos signos & lo que permite saber que se almacenan tres campos. El nombre de los campos queda a la izquierda del signo igual y se han usado sólo dos letras para definirlos. Como el nombre de los campos (o variables, si se prefiere) de la petición HTTP no guardan relación con los de la base de datos, no es especialmente importante usar textos descriptivos y suelen elegirse nombres breves (incluso campos numerados) para ahorrar texto en la comunicación con el servidor y aligerar el proceso de envío de datos.
Los datos que un dispositivo IoT envía normalmente al servidor son de tipo numérico, principalmente enteros y decimales sencillos. Cuando se envían valores en formato texto, como es el caso de la variable «ne» del ejemplo, pueden darse circunstancias desfavorables que pueden resolverse, según el caso, con más o menos éxito y facilidad. En esta ocasión se usan signos más (+) para separar las palabras en sustitución de los espacios que de otra forma alterarían la petición POST. Una forma genérica de enviar los datos que resuelve la mayoría de los casos es indicando el código hexadecimal de los caracteres, precedidos por el signo de porcentaje (%) Como es lógico, no conviene usar este recurso más que cuando lo codificado sea problemático ya que se aumenta la longitud de lo enviado lo que requiere en general más recursos aunque ciertamente se trate de dimensiones muy pequeñas.
Aunque es posible hacer funcionar un servidor web para Internet de las cosas sólo con la información del ejemplo anterior, muchos servidores, especialmente los públicos, añaden otros datos a la consulta POST (por desgracia no siempre limitados al protocolo) El ejemplo de abajo corresponde con la petición post que solicita el conocido servidor público para Internet de las cosas ThingSpeak.
|
1
2
3
4
5
6
7
8
|
POST /update HTTP/1.1
Host: api.thingspeak.com
Connection: close
X–THINGSPEAKAPIKEY: 1234567890
Content–Type: application/x–www–form–urlencoded
Content–Length: 23
1=10.25&2=–5.32&3=25.15
|
Además de algunos datos propios, como X-THINGSPEAKAPIKEY (y que corresponde con el identificador de cada cliente) en el ejemplo anterior puede verse que hay otras cabeceras que añaden más información a la petición.
La forma de usar una cabecera en una petición POST consiste simplemente en escribir su nombre, un signo de dos puntos (:) un espacio en blanco y el valor que se le quiere asignar.
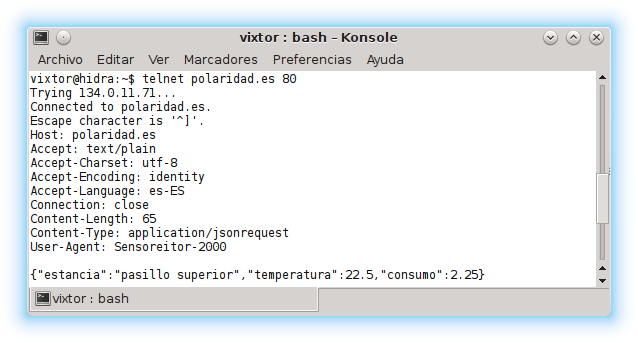
Para poder hacer pruebas de peticiones POST al servidor web antes de que terminar la configuración de los otros componentes puede establecerse una conexión con servidor y enviar manualmente los datos. Por ejemplo, en un ordenador con Linux bastaría con usar telnet polaridad.es 80 siendo polaridad.es el nombre del servidor y 80 el número de puerto en el que responde el servicio HTTP.
Tanto en Linux como en Windows o en OS X se puede usar la herramienta multiplataforma PuTTY, de la que se habló en el artículo control de dispositivos serie UART desde el ordenador, para realizar la conexión sin usar la consola.
En la siguiente lista de cabeceras HTTP están la mayoría de las que pueden resultar útiles para una petición POST a un servidor web para Internet de las cosas.
-
AcceptSirve para indicar el tipo MIME que la petición espera que el servidor use en la respuesta. Se expresa comotipo/subtipoque puede generalizarse utilizando como signo comodín el asterisco (*) por ejemplo como*/*para referirse a cualquiera otipo/*para referirse a todos los subtipos detipoLos más comúnmente usados son:
-
text/plainAunque es el más básico también es el más usado. Espera que el servidor devuelva como respuesta un texto sencillo (plano) que es suficiente para avisar de que la transacción ha sido correcta y a lo sumo añadir información accesoria como el número de orden de los datos grabados, el resultado de una comparación, la fecha del servidor… -
application/xmlotext/xmlEspera que el servidor responda a la petición en formato XML. El sentido de elegirtexten lugar deapplicationpermite una lectura «humana» (frente a «automática») más sencilla. Esta dualidad se presentará e otros tipos MIME pero la tendencia a futuro del estándar es preferirapplicationfrente atextEl formato XML permite estructurar de manera muy sólida una respuesta que contenga muchos datos, el inconveniente es que añade mucho artificio a los datos netos, lo que hace que la respuesta ocupe más de lo imprescindible, necesite por tanto más ancho de banda y seguramente más memoria en el dispositivo IoT para procesarla. -
text/htmlSe utiliza cuando la respuesta del servidor es HTML codificado como texto sencillo (texto plano) normalmente formateando una respuesta. Como se trata de almacenar datos y la respuesta llegaría a un pequeño dispositivo sin muchos recursos no es frecuente usar este tipo. -
application/xhtml+xmlBásicamente se trata de la versión XHTML (HTML como XML válido) de la información del apartado anterior. -
application/jsonEs el más usado cuando la respuesta del servidor contiene varios datos incluyendo una estructura más o menos compleja. El formato JSON comparte con el formato XML una estructura sólida y añade la ventaja de ser más escueto en el texto añadido por la estructura.
-
-
Accept-CharsetDetermina la codificación de texto que se pide que se use en la respuesta. Para codificar caracteres latinos suelen usarse el UTF-8, el más completo, ISO 8859-15, que incluye el signo del Euro (€) y el ISO 8859-1, que es el más básico. -
Accept-EncodingIndica el formato conforme al cual puede codificarse la respuesta del servidor. Básicamente sirve para indicar un tipo de compresión. Algunos de los más frecuentes songzipdeflate(que puede especificarse con más detalle condeflate-rawodeflate-http) No es habitual usarlo en pequeños dispositivos conectados a la Internet de las cosas ya que exige cierto consumo de recursos (memoria y tiempo de proceso) que suelen ser escasos en estos tipos de equipos. No es necesario indicar que no se usa la compresión conAccept-Encoding: identityya que se considera tal circunstancia por defecto. -
Accept-LanguageExpresa el idioma que puede utilizarse en la respuesta. Por ejemplo, el español de España se especificaría comoes-ESo el inglés de los Estados Unidos de América comoen-US -
ConnectionSirve para especificar lo que debe hacerse con la conexión que se ha establecido entre el cliente (el dispositivo IoT) y el servidor web una vez que se reciban los datos. Normalmente se usa con el valorcloseen el formatoConnection: closepara indicar que la conexión debe cerrarse después de responder al cliente. -
Content-LengthPermite indicar el número de bytes que ocupa la parte de la petición que contiene los datos, que es la que va después de las cabeceras y separada por una línea en blanco. Es muy útil puesto que sirve para verificar la integridad de la información que se envía; si no mide lo que se ha declarado no se almacena ya que se considera que no ha llegado correctamente. Suele ser exigida por la mayoría de los servidores IoT públicos. -
Content-TypeSirve para indicar el tipo MIME con el que se codifica la información que se envía al servidor. Suelen utilizarse los tipostext/htmlcuando se expresan como una lista de valores sencilla los datos que se mandan al servidor (algo comoa=3.6&b=4.8) yapplication/jsonrequest(que sería el equivalente al tipoapplication/jsondel que se habla enAccept) cuando es necesaria una estructura más compleja, pero puede enviarse cualquiera de la lista de tipos MIME. -
CookieSirve para añadir un identificador de sesión con el que mantener una cadena de transferencias (consulta, respuesta, consulta…) más compleja que una única petición con la que enviar determinados datos relacionados pero que se obtienen en diferentes momentos. -
RefererURL que ha originado la petición POST, por ejemplo la página web desde la que se envían. En el caso de usarse para IoT no añade información relevante ya que la información se envía directamente, sin una página previa, así que no es frecuente usarla. -
User-AgentInforma del dispositivo que realiza la petición. En el tráfico web habitual se trata del navegador para usarse en Internet de las cosas permite indicar al servidor el tipo de dispositivo electrónico que hace la petición. Al identificarse frente al servidor permite que la respuesta esté formateada de una forma diferente en cada caso, por ejemplo, devolviendo una página web compleja a un navegador y unos pocos datos de aviso a un pequeño dispositivo IoT
Es posible especificar una lista de opciones separadas por comas en lugar de un único valor en las cabeceras para indicar que se admiten simultáneamente varios valores distintos. Estos valores pueden tener un orden de prioridad que se expresa según un coeficiente de calidad q para cada uno. Los coeficientes de calidad se separan por un signo de punto y coma (;) y pueden usarse también asteriscos (*) para referirse a cualquier tipo o subtipo.
Accept: text/plain,text/xml,application/json;q=0.8,text/*;q=0.9,application/json
En el ejemplo anterior la prioridad del formato JSON es la mayor (0.9) la del texto plano y la del texto en formato XML, que cumplen la especificación text/*, es menor (0.8) e igual entre ellos. En caso de ser posible el servidor debería reaccionar codificando la respuesta como JSON.
En el siguiente ejemplo de una petición POST más completa se accede a la página /iot/grabar_temperatura del servidor llamado polaridad.es usando la versión 1.1 del protocolo HTTP. El cliente, llamado Sensoreitor-2000 envía los datos codificados en formato JSON, espera la respuesta como texto plano en formato UTF-8 usando el español de España sin usar compresión, cosa que, por cierto, no es necesario indicar. Los datos que se envían al servidor ocupan 65 bytes. Al enviar la respuesta la conexión entre el cliente y el servidor se cerrará.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
POST /iot/grabar_temperatura HTTP/1.1
Host: polaridad.es
Accept: text/plain
Accept–Charset: utf–8
Accept–Encoding: identity
Accept–Language: es–ES
Connection: close
Content–Length: 65
Content–Type: application/jsonrequest
User–Agent: Sensoreitor–2000
{«estancia»:«pasillo superior»,«temperatura»:22.5,«consumo»:2.25}
|
En el siguiente artículo se explica cómo configurar la base de datos MySQL para almacenar la información enviada por los objetos IoT


Publicar comentario