
asegura la distribución y replicación de datos de manera eficiente.
En el mundo actual, donde la cantidad de datos generados es cada vez mayor, es fundamental contar con herramientas que permitan asegurar la distribución y replicación de los mismos de manera eficiente. En este artículo, exploraremos algunas soluciones y estrategias que nos permiten alcanzar este objetivo, garantizando la disponibilidad, integridad y confidencialidad de los datos en todo momento.
Qué es la replicación de datos en una base de datos distribuida
La replicación de datos es un proceso crucial en una base de datos distribuida. Consiste en copiar y sincronizar datos entre múltiples instancias de la base de datos, asegurando que todos los usuarios tengan acceso a la misma información actualizada. La replicación de datos ayuda a mejorar la disponibilidad, escalabilidad y rendimiento de la base de datos, al permitir que los usuarios accedan a los datos desde diferentes ubicaciones geográficas y minimizar la latencia de la red.
La replicación de datos se puede configurar de varias maneras, dependiendo de los requisitos específicos de la aplicación y la infraestructura de la base de datos. Una forma común de replicación es la replicación maestro-esclavo, en la que un servidor maestro mantiene la base de datos principal y los servidores esclavos replican los cambios del maestro. Esto permite que los usuarios lean datos desde los servidores esclavos, mientras que los cambios se escriben en el servidor maestro.
Otra forma de replicación es la replicación de varios maestros, en la que múltiples servidores mantienen sus propias copias de la base de datos principal y se sincronizan entre sí. Esto es útil para aplicaciones que requieren una alta disponibilidad y capacidad de recuperación ante desastres. También hay técnicas de replicación más avanzadas, como la replicación de transacciones y la replicación de conflictos, que pueden ayudar a garantizar la consistencia y la integridad de los datos.
Para asegurar la distribución y replicación de datos de manera eficiente, es importante considerar varios factores clave. Uno de ellos es la topología de la red, que debe estar diseñada para minimizar la latencia y maximizar la velocidad de transferencia de datos. Otro factor es la elección del método de replicación adecuado, que debe ser seleccionado cuidadosamente en función de los requisitos de la aplicación y la infraestructura de la base de datos.
En resumen, la replicación de datos es un proceso crítico en una base de datos distribuida que permite a los usuarios acceder a la misma información actualizada desde diferentes ubicaciones geográficas. La elección del método de replicación adecuado y la configuración de la topología de la red son factores clave para asegurar la distribución y replicación de datos de manera eficiente.
Qué es replicación en sistemas distribuidos
En los sistemas distribuidos, la replicación de datos es un proceso clave para garantizar la disponibilidad y la eficiencia de los sistemas. La replicación consiste en crear copias de datos en diferentes ubicaciones, lo que permite acceder a ellos desde diferentes nodos de la red y aumentar la tolerancia a fallos.
La replicación puede ser síncrona o asíncrona. En la replicación síncrona, cada escritura en un nodo se replica en todos los demás nodos al mismo tiempo, lo que garantiza que todos los nodos tengan la misma versión de los datos en todo momento. En la replicación asíncrona, la escritura en un nodo se replica en otros nodos en un momento posterior, lo que permite una mayor escalabilidad y menor latencia en la escritura.
La replicación también puede ser activa o pasiva. En la replicación activa, todos los nodos pueden escribir y leer datos, lo que aumenta la disponibilidad de los datos. En la replicación pasiva, solo un nodo puede escribir datos, mientras que los demás nodos solo pueden leer datos, lo que reduce la carga de escritura en el sistema.
Para asegurar la distribución y replicación de datos de manera eficiente en un sistema distribuido, es importante considerar factores como la consistencia de datos, la latencia de red, la capacidad de almacenamiento y las políticas de replicación. Es necesario implementar estrategias de replicación adecuadas que equilibren la carga del sistema y minimicen la posibilidad de conflictos de datos.
Qué es la replicación de una base de datos y para qué se utiliza
La replicación de una base de datos es un proceso que permite crear y mantener copias idénticas de una base de datos en diferentes servidores o dispositivos de almacenamiento. La replicación se utiliza para garantizar la disponibilidad y la eficiencia de los datos, especialmente en entornos distribuidos o con alta carga de trabajo.
La replicación de una base de datos implica la copia y la sincronización de los datos entre diferentes nodos o servidores. Por lo general, se utiliza un servidor maestro o principal para mantener la copia principal de la base de datos, mientras que los servidores secundarios o esclavos mantienen copias de la base de datos que se sincronizan periódicamente con el servidor maestro.
La replicación de una base de datos tiene varios beneficios, entre los que se incluyen:
- Mejora la disponibilidad: al tener copias de la base de datos en diferentes servidores, se reduce el riesgo de pérdida de datos o interrupción del servicio debido a fallos en el hardware, el software o la red.
- Aumenta la escalabilidad: la replicación permite distribuir la carga de trabajo entre diferentes servidores, lo que puede mejorar el rendimiento y la capacidad de respuesta del sistema en general.
- Facilita la recuperación ante desastres: si se produce una falla en el servidor principal, los servidores secundarios pueden utilizarse para restaurar rápidamente la base de datos y minimizar el tiempo de inactividad.
Para implementar la replicación de una base de datos, es necesario utilizar un software especializado que permita configurar y administrar los diferentes servidores. Algunos de los sistemas de gestión de bases de datos más populares, como MySQL, PostgreSQL, SQL Server y Oracle, incluyen funcionalidades de replicación integradas.
En conclusión, asegurar la distribución y replicación de datos de manera eficiente es fundamental para garantizar la disponibilidad y la integridad de la información. La implementación de técnicas como la replicación geográfica, la compresión de datos y la utilización de redes de alta velocidad puede mejorar significativamente el rendimiento y la seguridad de los sistemas de almacenamiento y distribución de datos. Además, es importante considerar la escalabilidad y la flexibilidad de las soluciones adoptadas, para adaptarse a las necesidades cambiantes de las organizaciones y los usuarios. En definitiva, la eficiencia en la distribución y replicación de datos es clave para una gestión óptima de la información en la era digital.








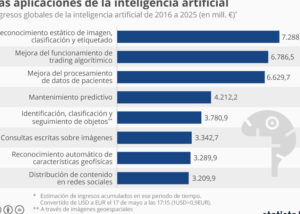

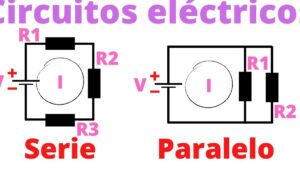



Post Comment