Librería de codificación Base64 con Arduino
Base64 es un sistema de codificación que utiliza 64 símbolos agrupados en mensajes que tienen una longitud múltiplo de cuatro. Estos mensajes (paquetes de datos) se completan, si es necesario, con un símbolo más (así que se usan 65), frecuentemente el signo igual (=), si la información útil codificada resulta en una longitud menor.
Usando 64 signos se puede trabajar con los 10 números y las letras mayúsculas y minúsculas (26+26) del código ASCII, el problema es que resultan 62 símbolos, digamos, no ambiguos más dos que varían en diferentes implementaciones. Aunque algunas veces se haga referencia con la expresión «caracteres ASCII imprimibles», en realidad son los que van desde el representado por el código 32 (el espacio) hasta el 126 (~) los 95 verdaderamente imprimibles.
La implementación de la codificación Base64 más utilizada, la del PEM, que también es la utilizada por MIME, trabaja con los signos extra «+» y «/» y el signo «=» para rellenar de manera que los paquetes tengan una longitud múltiplo de cuatro. Las letras A-Z ocupan las posiciones 0-25, las letras a-z las posiciones 26-51, los números 0-9 las posiciones 52-61, el signo más (+) la posición 62 y la posición 63 está ocupada por la barra (/).
La forma de representar los datos en formato Base64 consiste en ir tomando, de los datos originales, grupos de 6 bits que se representan con el código correspondiente. Si sobran bits se rellenan con ceros a la derecha. Si la cantidad de códigos resultante no es múltiplo de cuatro se rellena con signos igual a la derecha.
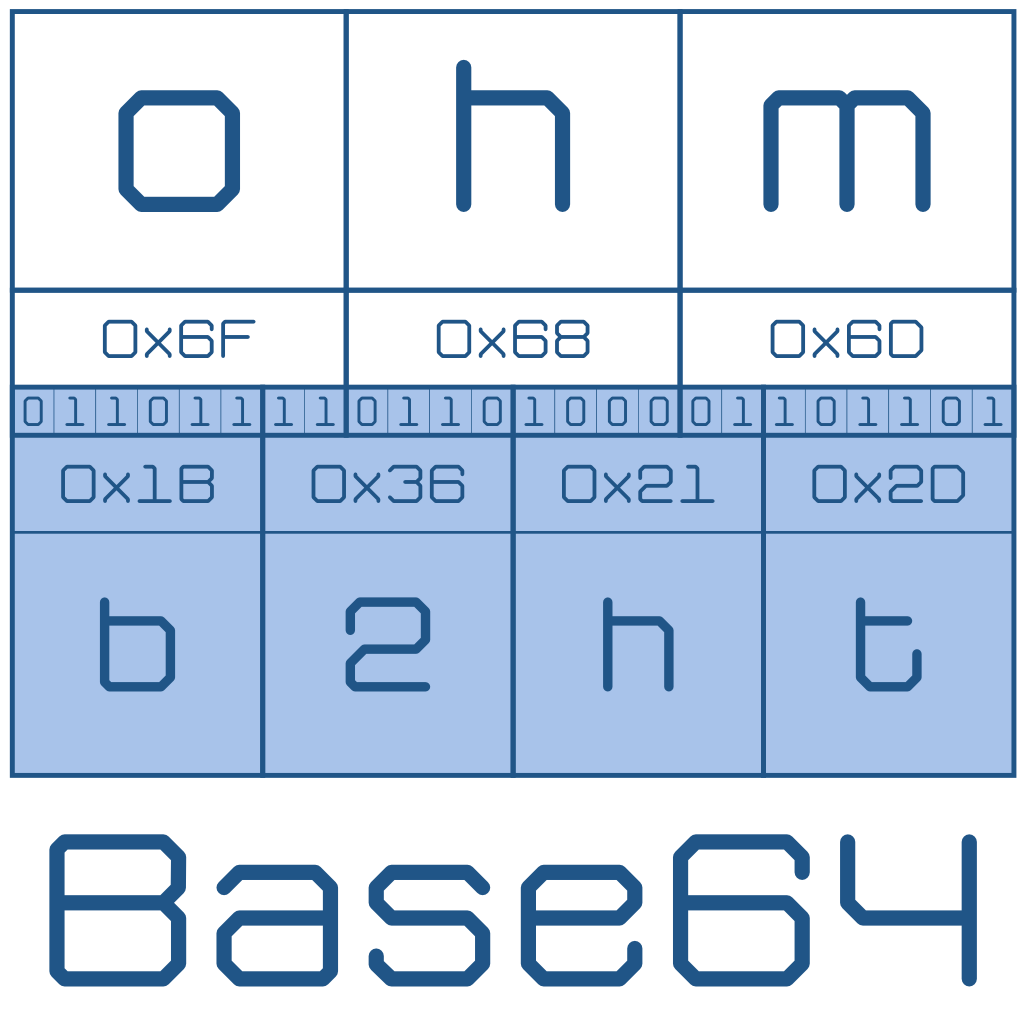
En la siguiente imagen se muestra la codificación ASCII de un texto («ohmio») y la forma en la que se convierte a Base64. Como resultan 7 símbolos, el mensaje final necesitaría el relleno de un signo igual al final. Podría decirse que el texto «ohmio» en ASCII equivale a «b2htaW8=» en Base64.

Los usos específicos de la codificación Base64 suelen imponer además una longitud máxima de línea. La implementación MIME limita a 76 caracteres cada línea. Normalmente las líneas se separarán por un código de fin de línea (CR, representado por el valor 0x0D en ASCII) y otro de nueva línea (NL, que corresponde al código ASCII 0x0A).
El inconveniente que se añade al implementar la codificación Base64 en un dispositivo con pocos recursos, como suele ser el caso de un microcontrolador es que hay que ir codificando a medida que llega la información o con un buffer mínimo, lo que exige, además, prever un sistema que indique que se ha llegado al final del mensaje original, por ejemplo, añadiéndole un código especial, o utilizando una patilla cuyo nivel (sincronizado con la recepción) indique el estado del mensaje.
El código de ejemplo de abajo es una librería para Arduino para codificar en Base64 que está implementado con ambos criterios: ir codificando la información que va llegando (sin un buffer) y esperar a una señal de aviso para terminar.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
//base64.h
#include <string.h> // memcpy/strncpy
#define LONGITUD_LINEA 76
#define MASCARA_B64 0B00111111
#define ULTIMO_CODIGO_BASE64 64 // 64 caracteres más el signo igual (empezando a contar desde cero)
#define MAXIMA_LONGITUD_RESULTADO 6 // Máximo número de caracteres del resultado parcial de la codificación. Puede ser 1 si no se ha llegado al final de un bloque (2 bytes en el original, 4 en la conversión), 2 si se ha llegado al final de un bloque, 3 si no se ha llegado al final de un bloque pero se supera la longitud máxima de la línea, 4 si se llega al final de un bloque y se supera la longitud máxima de la línea, 5 si hay que rellenar con un signo igual o 6 si hay que rellenar con dos signos igual
class Base64
{
private:
unsigned char simbolo_base64[ULTIMO_CODIGO_BASE64+1]; // Espacio para la codificación Base64, el relleno (=) una terminación en \0
unsigned int numero_valor; // Posición (empezando en cero) que ocupa el valor que se desea convertir en el mensaje completo original
unsigned int numero_codigo; // Posición del último código calculado. Podría limitarse al ancho de la línea (LONGITUD_LINEA, 76 caracteres) pero usando un contenedor alto se podría implementar también una cuenta estadística
unsigned char resto_base64; // Último resto obtenido al calcular el último código
unsigned char resultado[MAXIMA_LONGITUD_RESULTADO+1]; // Resultado de la conversión actual. Si es terminal puede incluir el caracter 65 (=) una o dos veces
unsigned char contador_caracteres_resultado=0;
void acumular_resultado(unsigned char valor);
public:
Base64();
~Base64();
void iniciar_conversion();
unsigned char *convertir(unsigned char valor_original, bool terminar_conversion);
unsigned char *convertir(unsigned char valor_original);
unsigned char *terminar();
};
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
|
//base64.cpp
#include “base64.h”
Base64::Base64() // Constructor
{
memcpy(simbolo_base64,“ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=”,ULTIMO_CODIGO_BASE64+1);
iniciar_conversion();
}
Base64::~Base64() // Destructor
{
}
void Base64::iniciar_conversion()
{
numero_valor=0;
numero_codigo=0;
resto_base64=0;
}
unsigned char *Base64::convertir(unsigned char valor_original, bool terminar_conversion) // Valor que se desea convertir a Base64
{
convertir(valor_original);
if(terminar_conversion)
{
terminar();
}
return resultado;
}
unsigned char *Base64::convertir(unsigned char valor_original) // Valor que se desea convertir a Base64
{
unsigned char desplazamiento;
contador_caracteres_resultado=0;
acumular_resultado((valor_original>>(2+(numero_valor%3)*2))|resto_base64);
desplazamiento=4–(numero_valor%3)*2;
resto_base64=(valor_original&(MASCARA_B64>>desplazamiento))<<desplazamiento;
if(((numero_codigo+1)%4==0))
{
acumular_resultado(resto_base64);
resto_base64=0;
}
numero_valor++;
resultado[contador_caracteres_resultado]=0;
return resultado;
}
unsigned char *Base64::terminar()
{
if(numero_codigo%4)
{
acumular_resultado(resto_base64);
while(numero_codigo%4)
{
acumular_resultado(ULTIMO_CODIGO_BASE64);
}
}
resultado[contador_caracteres_resultado]=0;
iniciar_conversion();
return resultado;
}
void Base64::acumular_resultado(unsigned char valor)
{
numero_codigo++;
resultado[contador_caracteres_resultado++]=simbolo_base64[valor];
if((numero_codigo%LONGITUD_LINEA)==0)
{
resultado[contador_caracteres_resultado++]=13; // CR “\r”
resultado[contador_caracteres_resultado++]=10; // LF “\n”
}
}
|
La parte fundamental del cálculo del código Base64 se realiza con la expresión:
(valor_original>>(2+(numero_valor%3)*2))|resto_base64
y el cálculo del resto con la expresión:
(valor_original&(MASCARA_B64>>desplazamiento))<<desplazamiento,
siendo desplazamiento un valor que se calcula con la expresión:
4-(numero_valor%3)*2
El proceso seguido para obtener a esas expresiones consiste en generalizar el cálculo de cada uno de los cuatro códigos Base64 que resultan al representar tres bytes del valor original.
Base64=((byte_1>>2)|resto)&0b00111111 |
resto=(byte_1&0b00000011)<<4 |
Base64=((byte_2>>4)|resto)&0b00111111 |
resto=(byte_2&0b00001111)<<2 |
Base64=((byte_3>>6)|resto)&0b00111111 |
resto=(byte_3&0b00111111)<<0 |
Base64=((byte_3>>0)|resto)&0b00111111 |
resto=(byte_3&0b00111111)<<0 |
Con el texto Base64 del pseudocódigo anterior se hace referencia al código en Base64 que se está calculando. Se ha utilizado la expresión byte_n para hacer referencia al enésimo byte que se está codificando. El texto resto representa los bits sobrantes del byte que se está codificando. Al empezar el cálculo se supone que el resto es cero
Por claridad, en el pseudocódigo anterior se ha incluido la máscara de 6 bits en el cálculo de todos los códigos, aunque solamente es necesaria para determinar el último de ellos, puesto que los demás se rotan de forma que se pierden siempre los dos bits más significativos.
Como puede verse, el cuarto código es todo resto y no es necesario calcular un resto después; solamente es necesario realizar, por tanto, tres pasos, uno por byte codificado. Es importante recordar que, si no se llegara a codificar un tercer byte en un paquete habría que rellenar con ceros a la derecha el último código Base64 obtenido.
Para generalizar, la rotación a la derecha de la expresión que calcula el código en Base64 se puede representar como 2+(numero_byte%3)*2 de forma que la parte dentro del paréntesis rotaría de cero a dos, resultando 2, 4 y 6 en cada paso. Desde luego no es la única forma de generalizar, pero he elegido esta por funcional y sobre todo por claridad. Dado que la máscara (AND) solamente era necesaria en el cuarto código y ya se visto que no es necesario calcularlo (es todo resto) no se incluye en la expresión final para simplificarla, aunque hay que recordar que del tipo de datos utilizado (byte) solamente se toman los 6 bits menos significativos.
La rotación a la izquierda del resto se puede generalizar de una manera análoga a la anterior. También puede observarse que la máscara que se aplica (AND) sufre la misma rotación de bits pero en el sentido contrario. Esa es la razón de calcular el desplazamiento con 4-(numero_valor%3)*2 antes de aplicarlo en el sentido correspondiente a cada parte de la expresión.
En el siguiente ejemplo se muestra cómo usar la librería para codificar una cadena de texto (recordad que Base64 puede utilizarse para cualquier conjunto de datos, como una imagen, por ejemplo). En el código siguiente hay un par de detalles que es interesante aclarar. En primer lugar, se ha utilizado un símbolo especial (el símbolo ~) para indicar el final del texto, en lugar de una señal hardware o de indicar la longitud del texto. Como es lógico, ese símbolo no puede formar parte de los datos que se codifican.
La segunda cuestión que hay que considerar, tan importante como evidente, es que el decodificador en el destino debe conocer cómo se representa la información que le llega. El texto incluye caracteres que no pertenecen al conjunto ASCII imprimible (del 32 al 126), las letras con tilde, por ejemplo. Arduino utilizará dos bytes (UTF-8) para representar estos caracteres. No se podrá utilizar sin más el habitual \0 como terminador de texto ya que, en muchos casos, el primer byte con el que se represente un carácter será precisamente cero.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
#include “base64.h”
char texto_prueba[]=“La bella y graciosa moza marchose a lavar la ropa.\nLa mojó en el arroyuelo y cantando la lavó.\nLa frotó sobre una piedra, la colgó de un abedul.\nDespués de lavar la ropa, la niña se fue al mercado.\nUn pastor vendía ovejas pregonando a viva voz:\nved qué oveja, ved qué lana, ved qué bestia, qué animal.\nLa niña la vio muy flaca, sin embargo le gustó.\nYo te pago veinte escudos y no discutamos más.\nVuelve la niña cantando muy contenta con su oveja.\nCuando llegaron al bosque la ovejita se escapó.\nLa niña desesperada arrojose encima de ella.\nVelozmente y con destreza aferrola por detrás.\nLlegaba por el camino jinete de altivo porte.\nDescendió de su caballo y a la niña le cantó…~”;
char *resultado;
Base64 base64;
void setup()
{
Serial.begin(9600);
#if defined(__AVR_ATmega32U4__) || defined(__AVR_ATmega16U4__) // ¿Es un Arduino Leonardo (ATmega32U4)?
while(!Serial){}; // Esperar a Arduino Leonardo
#endif
// Mostrar el texto original
unsigned int contador=0;
while(texto_prueba[contador]!=‘~’)
{
//Serial.println(String(texto_prueba[contador])+”=”+String(texto_prueba[contador],DEC));
Serial.print(String(texto_prueba[contador]));
contador++;
}
Serial.println(“\n”);
// Mostrar el texto codificado en Base64
contador=0;
while(texto_prueba[contador]!=‘~’)
{
resultado=base64.convertir(texto_prueba[contador],texto_prueba[contador+1]==‘~’);
byte contador_resultado=0;
while(resultado[contador_resultado]>0)
{
Serial.print(String(resultado[contador_resultado]));
contador_resultado++;
}
contador++;
}
}
void loop()
{
}
|
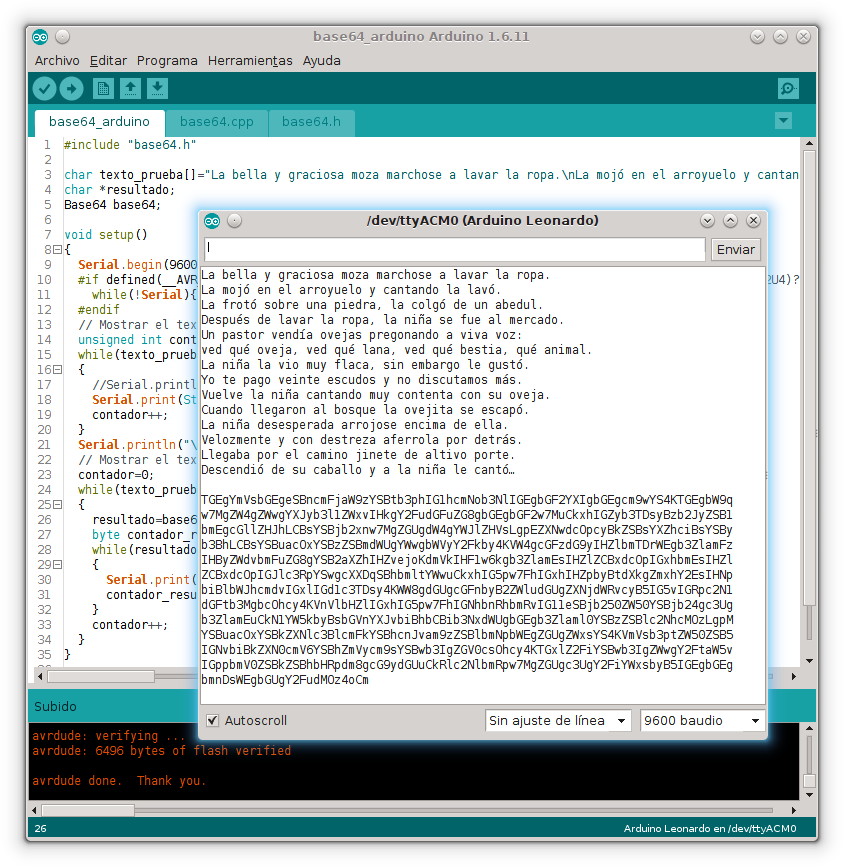
La línea 26 del ejemplo anterior muestra el uso de la librería para Arduino para codificar en Base64. Solamente es necesario ir indicando al método convertir cada byte que se desea codificar y opcionalmente si es el último o, en caso contrario, detener la conversión con el método terminar al llegar al final.
Como puede verse en la captura de pantalla de abajo, el programa de ejemplo de la librería para Arduino para codificar en Base64 muestra en primer lugar el texto que se va a codificar en Base64, en este caso, el principio de la famosa canción de los gigantes Les Luthiers, y posteriormente el resultado de codificar en Base64 utilizando la longitud de línea del formato MIME.


Post Comment